Łączenie elementów modelu danych PIM
Jak dotąd opisywałem kilka różnych elementów struktury PIM oddzielnie. Ich moc leży jednak w łączeniu. Różne techniki łączenia poszczególnych elementów modelu danych PIM, funkcjonalności systemów PIM i zasady opisujące te działania, to wszystko to nadal model danych PIM i zarządzanie nim.
Klasa w klasyfikacji może być połączona z wieloma atrybutami a te (jeśli są np. listą wyboru) potrafią mieć wiele predefiniowanych wartości. Niektóre systemy PIM pozwalają na łączenie klasyfikacji nie tylko z produktami, ale i z kategoriami. Jeśli kategorie połączone są z klasyfikacją, to wszystkie produkty w kategorii zyskują atrybuty przypisane do tej klasy.
Do niedawna częstą praktyką było łączenie klasyfikacji z kategoriami i przydzielanie tych samych atrybutów do produktów w danej kategorii. Wraz z popularyzacją nieustrukturyzowanych drzew kategorii oraz z coraz większym wymogiem udoskonalania danych produktowych model ten jest coraz rzadziej używany. Coraz częściej jednak produkty w jednej kategorii mogą należeć do różnych klas. Istnieje tendencja, szczególnie w branżach technicznych, do jak najdokładniejszego technicznego opisywania produktów. Co za tym idzie, np. złączki dwójniki, złączki trójniki czy złączki czwórniki należą do różnych klas z różnicami w atrybutach, pomimo że często znajdują się w jednej kategorii. Nie można więc założyć, że wszystkie produkty z kategorii znajdą się w tej samej klasie.
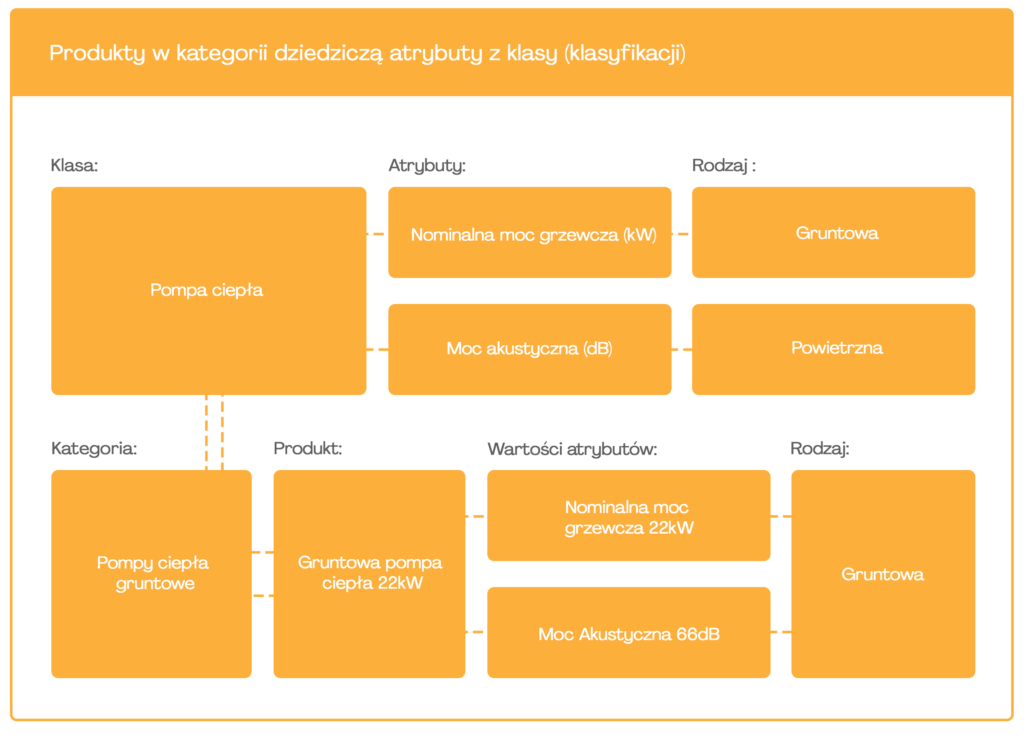
Zdjęcie 15 Produkty w kategorii dziedziczą atrybuty z klasy

Zdjęcie 16 Łączenie drzewa klasyfikacji do głównego drzewa kategorii
Tworzenie relacji dla klasyfikacji odbywa się obecnie hybrydowo (w bardziej zaawansowanych przypadkach). Klasy łączy się do kategorii. To klasa determinuje kategorię, w której powinien znaleźć się produkt a produkty łączy się do klas. Łączenie klas i kategorii w tym kierunku jest o wiele bardziej dokładne niż na odwrót, ale także niedoskonałe. Zawsze będą występowały sytuacje wyjątkowe (np. Złączki mają zastosowanie zarówno w instalacjach gazowych jak i wodnych – ale nie wszystkie). W takim przypadku tylko ręczna klasyfikacja i kategoryzacja produktu zda egzamin.
Tworzenie modelu danych PIM
Tworzenie modelu danych produktowych może być pracą wręcz laboratoryjną. Im więcej różnych rodzajów danych i rodzajów produktów tym więcej pracy trzeba wykonać, aby móc rozpocząć uzupełnianie danych.
Zanim jednak rozpoczniemy prace nad tworzeniem modelu trzeba mieć świadomość, że najprawdopodobniej do wykonania tego zadania będziemy musieli zaangażować wiele osób z całej organizacji. Często wymaga do sporządzenia wielu notatek, sporej ilości dokumentów itp. Warto zatem zadbać o organizację tej pracy aby możliwie najwydajniej przenosić zebrane informacje do tworzonego modelu oraz żeby sam model był przejrzysty i łatwy do aktualizacji. Przed sporządzeniem modelu danych PIM należy zaplanować:
- w jaki sposób będziemy zapisywać dane o modelu,
- kto będzie miał do niego dostęp,
- jakie będą obowiązywały zasady akceptacji zmian w obrębie modelu,
- za pomocą jakiego narzędzia model danych PIM będzie tworzony i utrzymywany.
Wyzwaniem jest fakt, że aby utworzyć wydajny i dobrze zaprojektowany model danych produktowych trzeba mieć spore doświadczenie w modelowaniu danych. Wymaga to także znajomości branży i samej firmy. Doświadczenie pokazuje, że ciężko jest znaleźć jedną osobę która posiada wszystkie te kompetencje.W związku z tym istnieje pewien zbiór rekomendacji do zastosowania podczas procesu tworzenia modelu danych:
Określ wewnętrzne główne drzewo kategorii
Na początek należy wyłonić wszystkie kategorie produktowe występujące w organizacji i zebrać je w intuicyjne drzewo. Często firmy posiadają takie podstawowe drzewo w ERP. Drzewo to posłuży jako podstawa do dalszych działań. Co bardzo istotne, drzewo to musi być intuicyjne dla pracowników organizacji. Ważne jest także, aby drzewo to było unikalne/ustrukturyzowane: kategorie nie powinny się powtarzać a produkty powinny należeć tylko do jednej kategorii.
Poniżej przykład:
- Pompy ciepła
- Pompy gruntowe
- Pompy powietrzne
- Pompy split
- Pompy monoblok
- Akcesoria do pomp
- Kotły
- Kotły gazowe
- Kotły na pellet
- Kotły olejowe
- Osprzęt do kotłów
Lista wszystkich atrybutów
Następnym krokiem jest stworzenie listy wszystkich atrybutów z podziałem na:
- Atrybuty globalne – dotyczące wszystkich klas produktów;
- Atrybuty zależne od klasy;
Jeżeli wiemy, że w naszej branży dostępna jest klasyfikacja zewnętrzna jak np. ETIM, to nie ma potrzeby wypisywania wszystkich atrybutów wynikających z tej klasyfikacji. Należy jednak określić z jakiej klasyfikacji będziemy korzystać i ew. z której jej wersji.
Lista atrybutów powinna być podzielona na grupy. Np.:
- Atrybuty podstawowe (ID, Nazwa, Marka);
- Atrybuty marketingowe (Opis);
- Atrybuty sprzedażowe i finansowe (Cena, Podatek);
- Atrybuty logistyczne (Wymiary, Waga);
- Media (Zdjęcia, Dokumenty);
- Atrybuty techniczne (Dotyczące konkretnej klasy);
Transformacja na strukturę klas
Kolejnym krokiem jest transformacja zebranych kategorii i atrybutów na klasy. Przy wykorzystaniu standardów klasyfikacji możemy ten krok mocno przyśpieszyć. Np.:
- Atrybuty globalne
- Nazwa
- ID
- Marka
- Opis
- Cena
- Podatek
- Wymiary
- Waga
- Zdjęcia
- Dokumenty
- Klasa: Pompy ciepła
- Atrybut techniczny: moc grzewcza
- Atrybut techniczny: moc chłodnicza
- Atrybut techniczny: moc akustyczna
- Klasa: Kotły
- Atrybut techniczny: moc grzewcza
- Atrybut techniczny: funkcyjność
- ITP.
Na tym etapie powinno się dogłębnie zastanowić które atrybuty faktycznie muszą być umieszczone na poziomie klasy. Jeśli umieścimy na poziomie klasy atrybut, który powinniśmy umieścić na poziomie globalnym to znacząco podniesie redundancję danych i utrudni pracę. Przy wykorzystaniu gotowych klasyfikacji jak np. ETIM sytuacja jest prostsza. Tylko atrybuty tej klasyfikacji znajdują się na poziomie klasy.
Wzbogacanie każdego atrybutu
Model danych PIM wymaga maksymalnej możliwej szczegółowości. Każdy z zebranych atrybutów musi zostać zatem dodatkowo wzbogacony, aby ułatwić (a czasami umożliwić) proces wdrożenia oraz wzbogacić dane. Kilka przykładów:
- Opis atrybutu: może być pomocne, aby po krótce opisać czego dotyczy atrybut. Wydaje się, że niektóre z przytoczonych atrybutów nie potrzebują opisów, bo ich nazwa wszystko tłumaczy. W rzeczywistości zdarzają się różne definicje wewnątrz jednej firmy nawet dla takiego atrybutu jak Marka.
- Typ atrybutu: np. Logiczny, Znaki, Tekst itp.
- Rodzaj miary: jeśli atrybut będzie posiadał wartości opatrzone miarą należy podać podstawową jednostkę.
- Lista wartości: jeśli atrybut będzie listą wyboru (pojedynczego lub wielokrotnego) to należy zdefiniować listę dostępnych wartości.
- Wymagalność: czy atrybut jest wymagalny czy nie. Jeśli tak, nie będzie można stworzyć/zapisać produktu który nie będzie miał ustawionej wartości w tym atrybucie.
- Restrykcje: restrykcje (walidacja) określają w jaki sposób powinny wyglądać dane wprowadzone do tego atrybutu. Np.:
- Posiada minimalną wartość
- Posiada maksymalną wartość
- Akceptuje liczby z przecinkiem
- Akceptuje liczby ujemne
- Regex
- itp.
- Atrybut determinujący wariant: w większości systemów PIM atrybut determinujący wariant musi być typu listy pojedynczego wyboru. Należy określić czy atrybut ten będzie determinował warianty produktu.
- Atrybut wynikający z wariantu: czy wartość tego atrybutu będzie się zmieniała wraz z wybranym wariantem ale jednocześnie atrybut tych wariantów nie determinuje.
- Źródło danych tego atrybutu: skąd będą pochodzić dane do tego atrybutu. Czy będziemy uzupełniać ten atrybut ręcznie czy może system pobierze dane z innego systemu? Bardzo często źródłem danych będzie system ERP lub inne zewnętrzne źródło. Dla niektórych danych system ERP przekaże wartości tylko raz i od tego czasu to PIM będzie głównym źródłem ten informacji.
- Atrybut synchronizowany: czy atrybut korzystający z zewnętrznego źródła oprócz jednorazowego uzupełnienia będzie stale synchronizowany (np. cena).
- Kanały i języki: czy atrybut będzie posiadał oddzielne wersje dla kanałów lub/i języków. Jeśli tak to należy opisać wszystkie warianty.
- Filtry i wyszukiwanie: czy atrybut będzie wykorzystywany jako filtr lub/i element wyszukiwania.
- Uprawnienia: czy uprawnienia do wyświetla lub/i edycji atrybutu będą zależne od użytkownika lub grupy użytkowników? Jeśli tak, to jak mają wyglądać te ograniczenia.
- Wyświetlanie: czy atrybut będzie wyświetlany w danym kanale lub kraju czy nie.
Utrzymanie i zarządzanie modelem danych produktowych
Model danych PIM jest elementem fundamentalnym i nieskończonym. Oznacza to, że praca nad nim jest procesem a nie projektem – nigdy się nie kończy. Z czasem dodaje się nowe kategorie, zmienia atrybuty, aktualizuje opcje atrybutów itp. Często opinie klientów, analizy czy rozmowy biznesowe wskazują na potrzebę dodania nowych danych strukturalnych jak atrybuty czy kanały sprzedaży.
Niezależnie od przyczyny powstania potrzeby aktualizacji modelu danych produktowych należy dbać o odpowiednie przechowywanie dokumentacji dotyczącej modelu i jej aktualizowanie.
Nieopracowany model danych PIM i zagrożenia z tego wynikające
Wraz z czasem, po wielu zmianach w modelu danych, po zmianach osób odpowiedzialnych za PIM może się okazać, że wiedza o tym jak wykorzystywany jest np. dany atrybut, z czym się łączy i skąd pochodzą do niego dane może się zatrzeć lub zaginąć, jeśli dokumentacja nie będzie aktualna. Łatwo wówczas o poważne błędy skutkujące koniecznością wgrywania kopii zapasowych czy innych prac IT.
Jak opisywałem wyżej, pomiędzy wieloma elementami struktury danych produktowych istnieją relacje. Sporo z tych elementów posiada także relacje zewnętrzne np. w zakresie pobierania wartości danego atrybutu. Są to aspekty często niewidoczne dla zwykłego użytkownika. Bez spisania i opisania tych elementów wiele modyfikacji struktury danych będzie potencjalną pułapką. To co wydawało nam się nie mieć wpływu na nic okazuje się kluczowym elementem w procesie np. fakturowania. Bardzo często atrybuty i ich wartości integruje się z różnymi systemami. Integracje takie mogą działać w różny sposób, np. pobierane są nazwy lub kody atrybutów. Zmiana tychże spowoduje, że te dane nie zostaną przesłane lub nawet cały mechanizm integracji przestanie działać.
Z czasem zacierają się także ważne informacje np. dotyczące powodów stworzenia danego atrybutu. Okazuje się, że nikt za bardzo nie wie w jakim celu zbieramy konkretne. Nie zauważymy takich problemów przy najbardziej podstawowych elementach modelu. Problem tego typu zaskakuje nas zazwyczaj przy flagach, oznaczeniach i podobnych typach atrybutów. Miałem wiele takich sytuacji przy projektach przy których pracowałem. Jeśli pojawi się potrzeba np. uporządkowania pewnych danych i skasowania nieużywanych oraz nie mając wiedzy na temat genezy powstania danego np. atrybutu oraz tego jak jest wykorzystywany pozostają nam trzy ścieżki:
- zostawić go jak jest i nie ryzykować – to tak naprawdę przesuwa problem w czasie;
- usunąć taki atrybut i „zobaczyć co się stanie” – ryzyko ogromne;
- przeanalizować wszystkie integracje i systemy pobierające dane z PIM i spróbować określić gdzie dana wartość jest wykorzystywana;
Żadna z nich nie jest dobra i optymalna. A nie istniałaby potrzeba wybierania pomiędzy nimi gdyby ktoś stworzył model danych PIM i go aktualizował.
Pozostałe wpisy:
- Podstawy PIM część 1
- Podstawy PIM część 2
- Korzyści PIM
- Model danych produktowych część 1
- Model danych produktowych część 2
- Procesy PIM część 1
- Procesy PIM część 2
- Procesy PIM część 3
- Wybór systemu PIM
- Wdrożenie systemu PIM część 1
- Wdrożenie systemu PIM część 2
Moje usługi:
Źródła:
- https://e-tropiki.pl screeny sklepu internetowego strony
- https://www.logovibe.pl projekty grafik
- https://nexpid.com moja wiedza i doświadczednie
- http://en.wikipedia.org/wiki/Product_information_management
- Rama całej wiedzy przekazywanej w tej stronie oparta jest na dziele w obszarze PIM J. Abraham, Product Information Management. Zachęcam do zakupu i poszerzenia wiedzy.
- A.T. Kearney, Action Plan to Accelerate Trading Partner Electronic Collaboration, Data
- Synchronization Proof of Concept: Case Studies from Leading Manufacturers and Retailers.
- The Yankee Group, The Cost of Waiting: Building the ROI Case to Implement Product
Information Management Now. - Aberdeen Group, The Instant Power of All-Channel PIM: Increased Sales and Competitiveness,
December - Konst, J. S., la Fontaine, J. P., & Hoogeboom, M. G. R. (2009, August). Product data management, a strategic perspective. Geldermalsen: Maj Engineering Publishing.
- GoodmastersHQ.com presentation
- Heiler PIM ROI Study
- http://www.pim-verzeichnis.de/
- Forrester, 2009
- GoodmastersHQ.com presentation, July 2012.
- http://en.wikipedia.org/wiki/Product_classification
- http://faculty.philau.edu/russowl/product.html
- http://proclass.org.uk
- http://en.wikipedia.org/wiki/Net_Promoter